MOJO-AUDIO
COMPILING _High-performance audio DSP library that beats librosa
Overview
mojo-audio is a high-performance audio DSP library written from scratch in Mojo. Built specifically for Whisper speech-to-text preprocessing, it generates mel spectrograms faster than librosa across all audio lengths.
We started 31.7x slower than librosa. After 10 optimization stages, we beat it everywhere—pure Mojo outperforming NumPy/SciPy’s optimized C backends.
Active Development
This library is under active development as part of the Mojo Voice project. API may change. Production use at your own risk.
Performance
Whisper audio preprocessing (random audio, fair comparison):
1 second 10 seconds 30 seconds
librosa: 2-3ms 10ms 26-37ms
mojo-audio: ~1ms ~7ms ~20ms
Result: Mojo wins across all durations
2-3x faster on short audio
20-27% faster on long audio🎮 Try the Interactive Demo
Run live benchmarks in your browser with configurable parameters. Compare mojo-audio vs librosa across different audio durations, FFT sizes, and BLAS backends.
Launch Demo →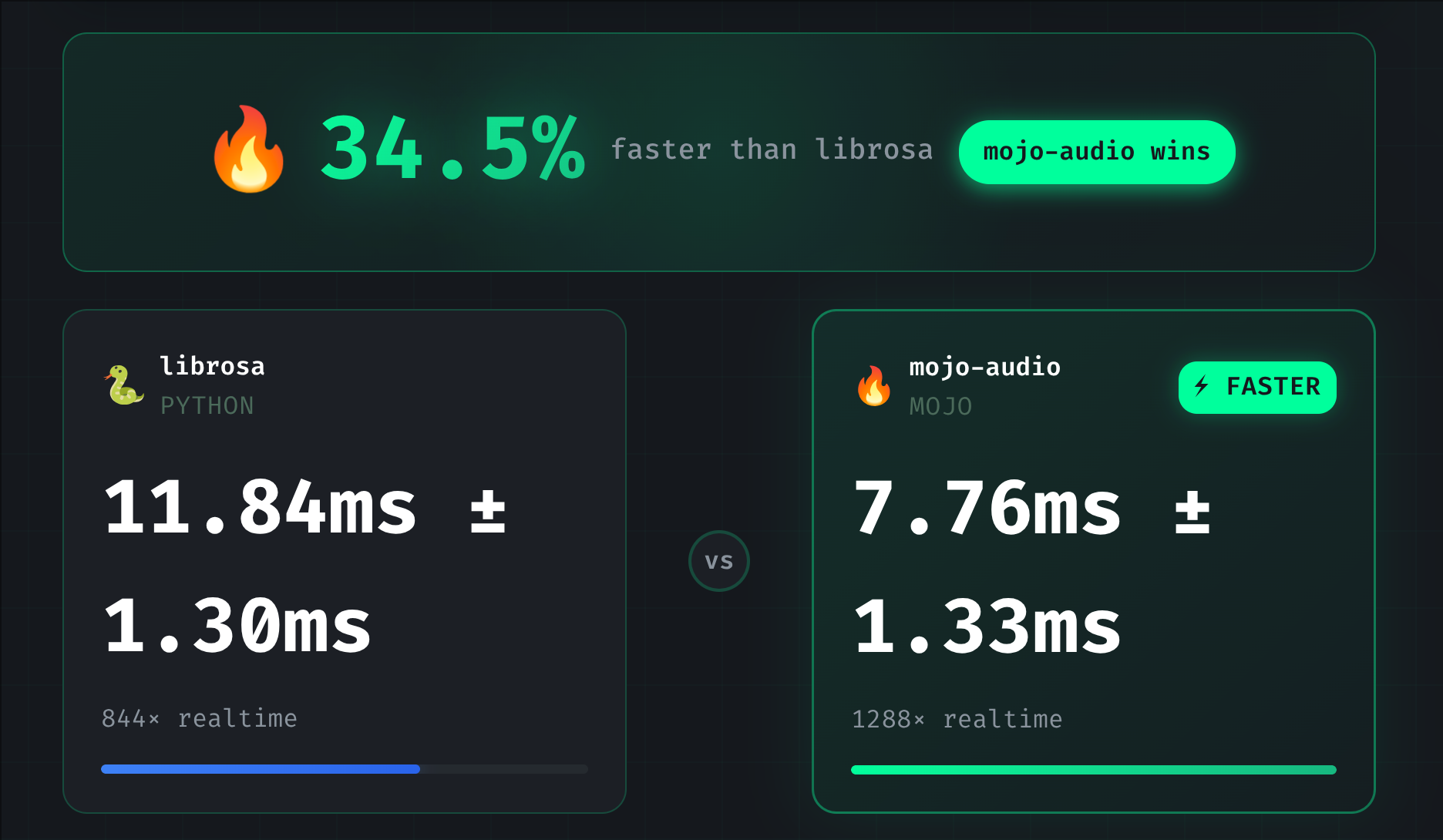

Key Features
- Drop-in Whisper preprocessing (16kHz, 400-sample FFT, 80 mel bands)
- No external dependencies—full control over memory layout
- SIMD-optimized FFT and filterbank operations
- C-compatible API for Rust/Python/Go integration
- Validates against Whisper’s expected output
Why We Built This
We’re building Mojo Voice—a developer-focused voice-to-text app. We needed mel spectrogram preprocessing for our Whisper pipeline but ran into issues with existing implementations.
Instead of debugging someone else’s abstractions, we built our own from scratch. The result: full control over correctness and performance, and a genuine technical differentiator.
Architecture
The pipeline matches OpenAI Whisper’s expected input:
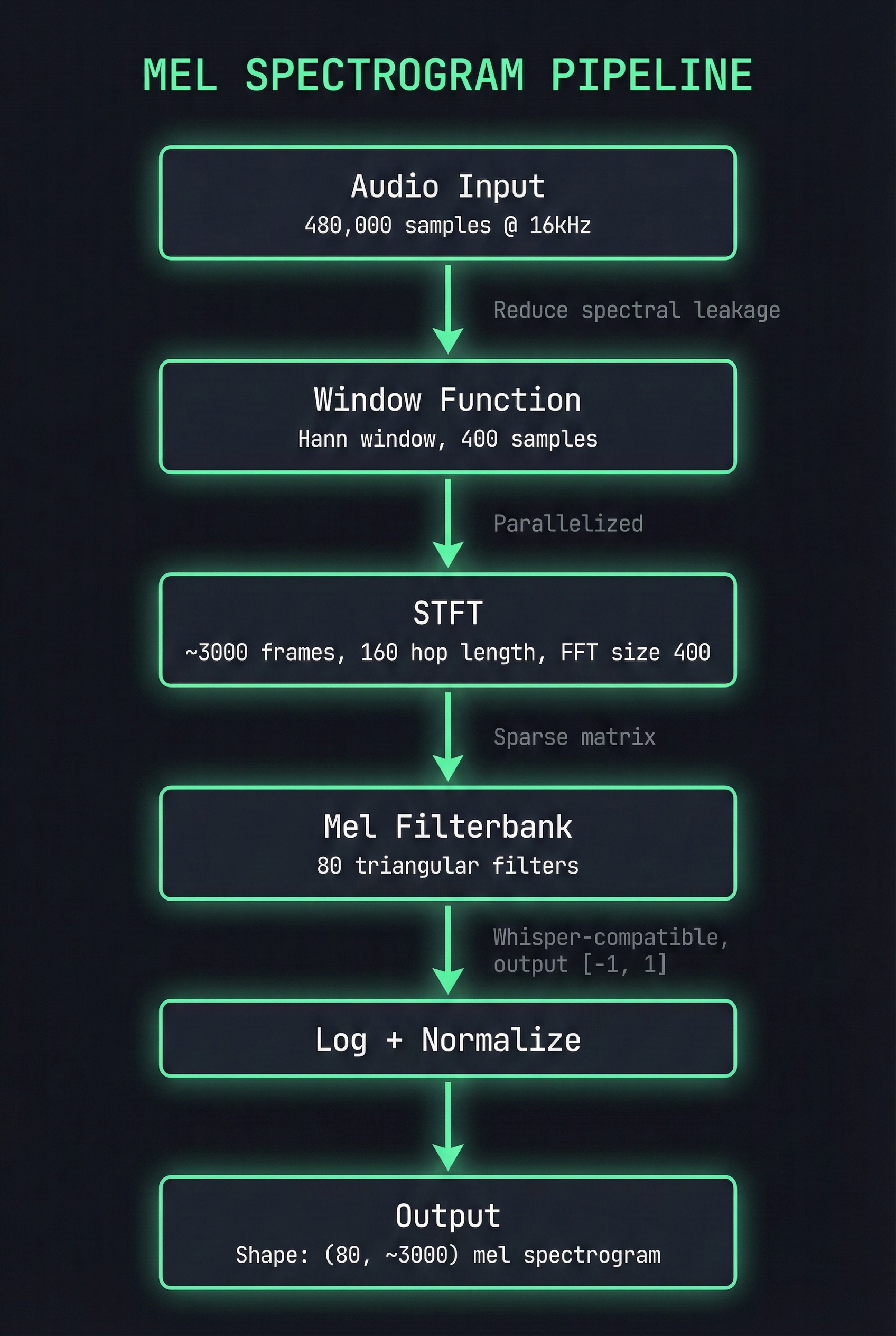
- Audio Input → 16kHz sample rate
- Window Function → 400-sample Hann window (25ms)
- STFT → Short-time Fourier transform with 160-sample hop (10ms)
- Mel Filterbank → 80 mel bands
- Log + Normalize → Final mel spectrogram output
Key design decisions:
- SoA layout for SIMD efficiency (real/imaginary stored separately)
- 64-byte alignment matching cache line size
- Handle-based FFI for clean cross-language integration
- Pre-computed twiddle factors reused across frames
The Optimization Journey
| Stage | Technique | Speedup | What We Did |
|---|---|---|---|
| 0 | Naive | — | Recursive FFT, allocations everywhere |
| 1 | Iterative FFT | 3.0x | Cooley-Tukey, cache-friendly |
| 2 | Twiddle caching | 1.3x | Pre-compute sine/cosine |
| 3 | Memory pooling | 1.2x | Eliminate per-frame allocations |
| 4 | SoA layout | 1.3x | SIMD-friendly data structure |
| 5 | Vectorized FFT | 1.6x | SIMD butterfly operations |
| 6 | Filterbank fusion | 1.5x | Single-pass mel computation |
| 7 | Alignment | 1.1x | 64-byte cache alignment |
| 8 | Parallelization | 1.5x | Multi-core frame processing |
| 9 | Final tuning | 1.1x | Branch hints, unrolling |
Total: 24x internal speedup (476ms → ~20ms for 30s audio)
Read the Deep Dive
For the full technical breakdown—including what failed and why—read the blog post:
Building a Fast Mel Spectrogram Library in Mojo
Installation
# Clone the repository
git clone https://github.com/itsdevcoffee/mojo-audio
# Build (requires Mojo SDK)
mojo build -o mojo-audio src/main.mojoUsage
from mojo_audio import MelSpectrogram
# Create processor (matches Whisper defaults)
processor = MelSpectrogram(
sample_rate=16000,
n_fft=400,
hop_length=160,
n_mels=80
)
# Process audio
mel = processor.compute(audio_samples)FFI Integration
mojo-audio exposes a C-compatible API for integration with Rust, Python, or Go:
// C header
MojoAudioHandle* mojo_audio_create(int sample_rate, int n_fft, int hop_length, int n_mels);
float* mojo_audio_compute(MojoAudioHandle* handle, float* samples, int num_samples);
void mojo_audio_destroy(MojoAudioHandle* handle);Contributing
This project is part of the Mojo Voice ecosystem. Contributions welcome—especially:
- Additional audio processing functions
- Performance improvements
- Language bindings
- Documentation
Check the GitHub repository to get started.